
Les LLM (pour Large Language Models ou « Grand Modèles de Langage » en français) peu efficaces risquent bientôt de devenir un vestige du passé grâce au nouveau UltraFastBERT de l’ETH Zurich, qui affiche une vitesse de 78x en n’utilisant que 0,3% des neurones d’un modèle de langage 🤯
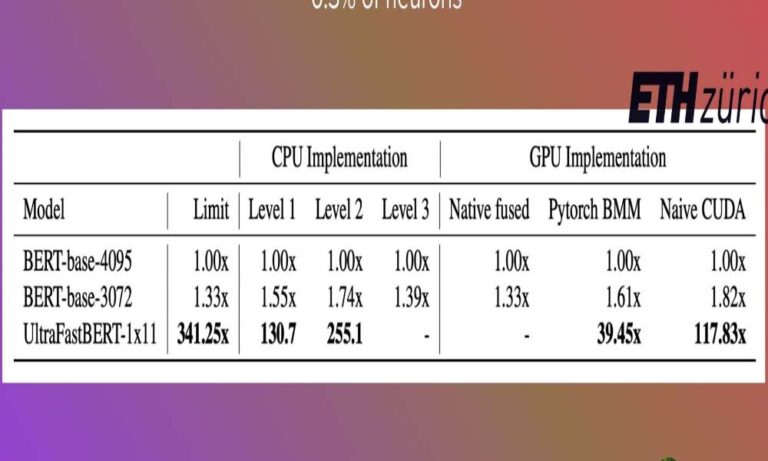
Imaginez un modèle BERT si efficace qu’il n’utilise que 0,3 % de ses neurones au cours de l’inférence sans pour autant compromettre les performances. C’est ce que propose UltraFastBERT, une variante de BERT de l’ETH Zurich qui réinvente l’efficacité en n’engageant sélectivement que 12 des 4095 neurones par couche pendant l’inférence.
Le résultat se traduit par une accélération stupéfiante de 78 fois par rapport aux implémentations de base optimisées.
En quoi est-ce important ? La méthode UltraFastBERT permet de réduire considérablement la complexité des calculs. Tandis que la plupart des modèles de langage engagent tous les neurones pour chaque calcul, UltraFastBERT agit sur une échelle logarithmique, ce qui permet de réduire sensiblement le temps de traitement et d’ouvrir la voie à un traitement plus efficace des langues sur divers types de matériel.
Des modèles moins coûteux et plus rapides débloqueront une multitude d’applications commerciales.
Publication https://lnkd.in/ghNkPy5R
Modèle https://lnkd.in/gdpzgUri
Rejoignez des milliers de chercheurs et d’ingénieurs de réputation mondiale de Google, Stanford, OpenAI et Meta pour rester à la pointe de l’IA http://aitidbits.ai